 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHELIX: Hybrid Encoding with Learnable Identity and Cross-dimensional Synthesis for Time Series Imputation
May 04, 2026Time series imputation benefits from leveraging cross-feature correlations, yet existing attention-based methods re-discover feature relationships at each layer, lacking persistent anchors to maintain consistent representations. To address this, we propose HELIX, which assigns each feature a learnable feature identity, a persistent embedding that captures intrinsic semantic properties throughout the network. Unlike graph-based methods that rely on predefined topology and assume homogeneous spatial relationships, HELIX learns arbitrary feature dependencies end-to-end from temporal co-variation, naturally handling datasets where features mix spatial locations with semantic variables. Integrated with hybrid temporal-feature attention, HELIX achieves the state-of-the-art performance, surpassing all 16 baselines on 5 public datasets across 21 experimental settings in our evaluation. Furthermore, our mechanistic analysis reveals that HELIX aligns learned feature identities and dependencies with latent physical and semantic structure progressively across layers, demonstrating that it more effectively translates cross-feature structure into imputation accuracy.
A Cautionary Tale of Self-Supervised Learning for Imaging Biomarkers: Alzheimer's Disease Case Study
Jan 23, 2026Discovery of sensitive and biologically grounded biomarkers is essential for early detection and monitoring of Alzheimer's disease (AD). Structural MRI is widely available but typically relies on hand-crafted features such as cortical thickness or volume. We ask whether self-supervised learning (SSL) can uncover more powerful biomarkers from the same data. Existing SSL methods underperform FreeSurfer-derived features in disease classification, conversion prediction, and amyloid status prediction. We introduce Residual Noise Contrastive Estimation (R-NCE), a new SSL framework that integrates auxiliary FreeSurfer features while maximizing additional augmentation-invariant information. R-NCE outperforms traditional features and existing SSL methods across multiple benchmarks, including AD conversion prediction. To assess biological relevance, we derive Brain Age Gap (BAG) measures and perform genome-wide association studies. R-NCE-BAG shows high heritability and associations with MAPT and IRAG1, with enrichment in astrocytes and oligodendrocytes, indicating sensitivity to neurodegenerative and cerebrovascular processes.
Multiscale Cross-Modal Mapping of Molecular, Pathologic, and Radiologic Phenotypes in Lipid-Deficient Clear Cell Renal CellCarcinoma
Dec 13, 2025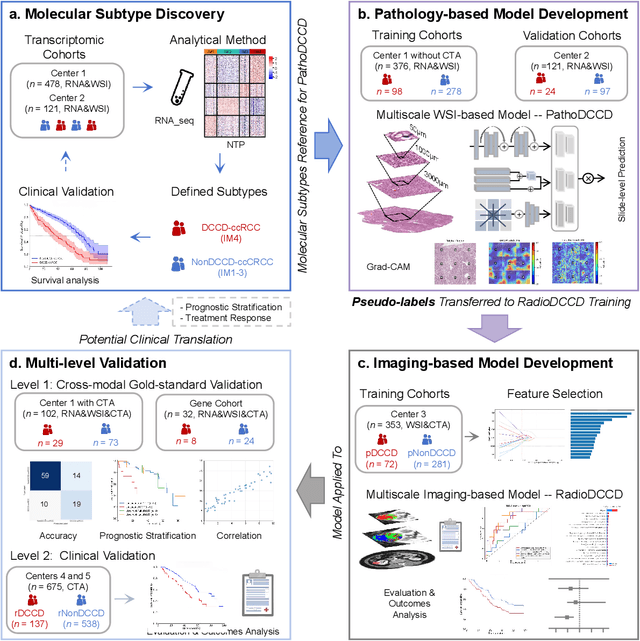
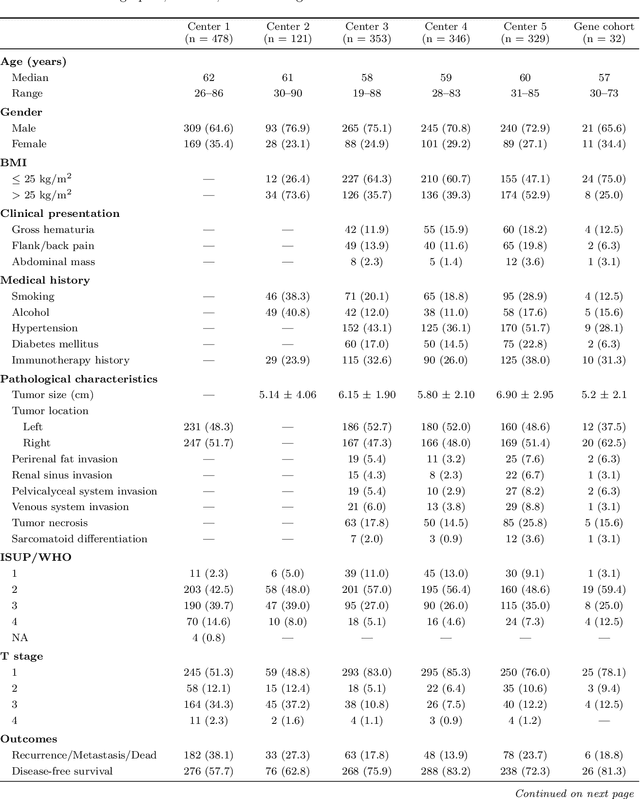
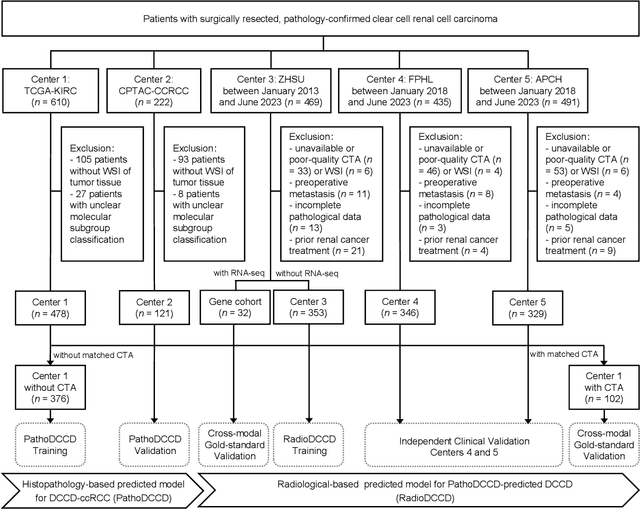
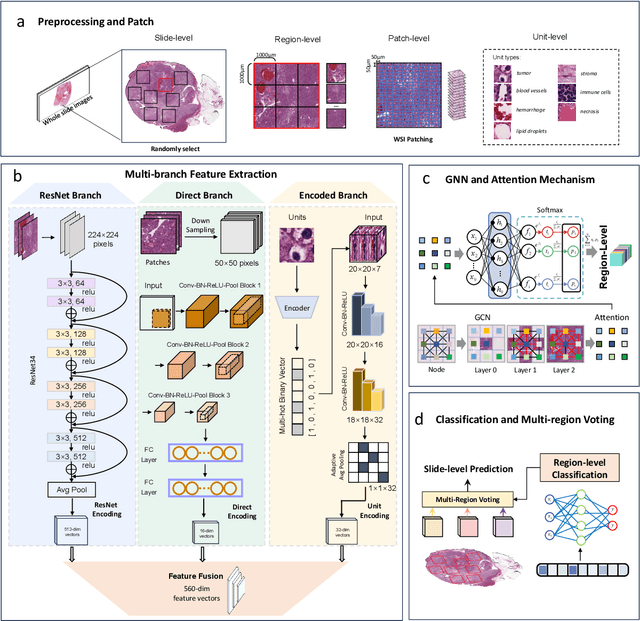
Clear cell renal cell carcinoma (ccRCC) exhibits extensive intratumoral heterogeneity on multiple biological scales, contributing to variable clinical outcomes and limiting the effectiveness of conventional TNM staging, which highlights the urgent need for multiscale integrative analytic frameworks. The lipid-deficient de-clear cell differentiated (DCCD) ccRCC subtype, defined by multi-omics analyses, is associated with adverse outcomes even in early-stage disease. Here, we establish a hierarchical cross-scale framework for the preoperative identification of DCCD-ccRCC. At the highest layer, cross-modal mapping transferred molecular signatures to histological and CT phenotypes, establishing a molecular-to-pathology-to-radiology supervisory bridge. Within this framework, each modality-specific model is designed to mirror the inherent hierarchical structure of tumor biology. PathoDCCD captured multi-scale microscopic features, from cellular morphology and tissue architecture to meso-regional organization. RadioDCCD integrated complementary macroscopic information by combining whole-tumor and its habitat-subregions radiomics with a 2D maximal-section heterogeneity metric. These nested models enabled integrated molecular subtype prediction and clinical risk stratification. Across five cohorts totaling 1,659 patients, PathoDCCD reliably recapitulated molecular subtypes, while RadioDCCD provided reliable preoperative prediction. The consistent predictions identified patients with the poorest clinical outcomes. This cross-scale paradigm unifies molecular biology, computational pathology, and quantitative radiology into a biologically grounded strategy for preoperative noninvasive molecular phenotyping of ccRCC.
SRLR: Symbolic Regression based Logic Recovery to Counter Programmable Logic Controller Attacks
Dec 12, 2025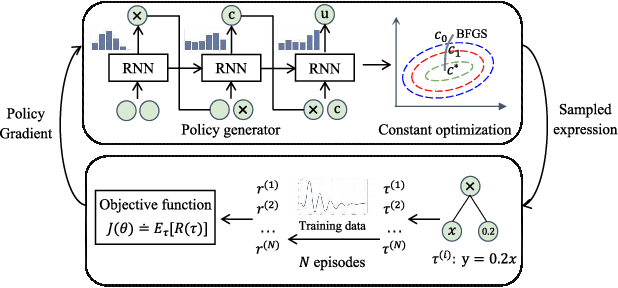
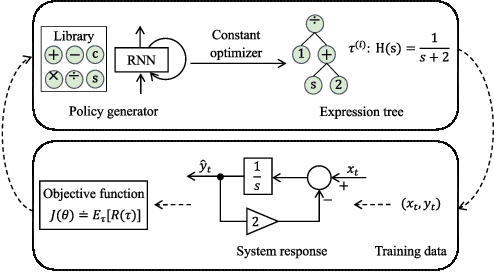
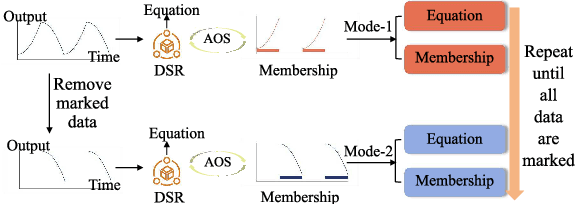
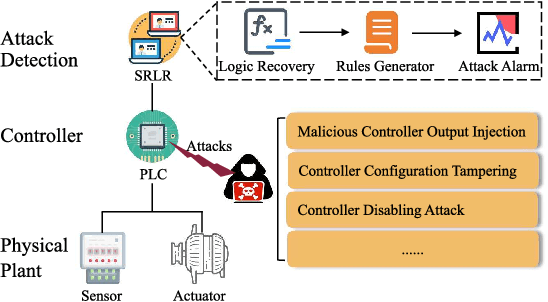
Programmable Logic Controllers (PLCs) are critical components in Industrial Control Systems (ICSs). Their potential exposure to external world makes them susceptible to cyber-attacks. Existing detection methods against controller logic attacks use either specification-based or learnt models. However, specification-based models require experts' manual efforts or access to PLC's source code, while machine learning-based models often fall short of providing explanation for their decisions. We design SRLR -- a it Symbolic Regression based Logic Recovery} solution to identify the logic of a PLC based only on its inputs and outputs. The recovered logic is used to generate explainable rules for detecting controller logic attacks. SRLR enhances the latest deep symbolic regression methods using the following ICS-specific properties: (1) some important ICS control logic is best represented in frequency domain rather than time domain; (2) an ICS controller can operate in multiple modes, each using different logic, where mode switches usually do not happen frequently; (3) a robust controller usually filters out outlier inputs as ICS sensor data can be noisy; and (4) with the above factors captured, the degree of complexity of the formulas is reduced, making effective search possible. Thanks to these enhancements, SRLR consistently outperforms all existing methods in a variety of ICS settings that we evaluate. In terms of the recovery accuracy, SRLR's gain can be as high as 39% in some challenging environment. We also evaluate SRLR on a distribution grid containing hundreds of voltage regulators, demonstrating its stability in handling large-scale, complex systems with varied configurations.
* 27 pages, 20 figures. This article was accepted by IEEE Transactions on Information Forensics and Security. DOI: 10.1109/TIFS.2025.3634027
Training-Free Dual Hyperbolic Adapters for Better Cross-Modal Reasoning
Dec 09, 2025Recent research in Vision-Language Models (VLMs) has significantly advanced our capabilities in cross-modal reasoning. However, existing methods suffer from performance degradation with domain changes or require substantial computational resources for fine-tuning in new domains. To address this issue, we develop a new adaptation method for large vision-language models, called \textit{Training-free Dual Hyperbolic Adapters} (T-DHA). We characterize the vision-language relationship between semantic concepts, which typically has a hierarchical tree structure, in the hyperbolic space instead of the traditional Euclidean space. Hyperbolic spaces exhibit exponential volume growth with radius, unlike the polynomial growth in Euclidean space. We find that this unique property is particularly effective for embedding hierarchical data structures using the Poincaré ball model, achieving significantly improved representation and discrimination power. Coupled with negative learning, it provides more accurate and robust classifications with fewer feature dimensions. Our extensive experimental results on various datasets demonstrate that the T-DHA method significantly outperforms existing state-of-the-art methods in few-shot image recognition and domain generalization tasks.
Rethinking Text-based Protein Understanding: Retrieval or LLM?
May 26, 2025In recent years, protein-text models have gained significant attention for their potential in protein generation and understanding. Current approaches focus on integrating protein-related knowledge into large language models through continued pretraining and multi-modal alignment, enabling simultaneous comprehension of textual descriptions and protein sequences. Through a thorough analysis of existing model architectures and text-based protein understanding benchmarks, we identify significant data leakage issues present in current benchmarks. Moreover, conventional metrics derived from natural language processing fail to accurately assess the model's performance in this domain. To address these limitations, we reorganize existing datasets and introduce a novel evaluation framework based on biological entities. Motivated by our observation, we propose a retrieval-enhanced method, which significantly outperforms fine-tuned LLMs for protein-to-text generation and shows accuracy and efficiency in training-free scenarios. Our code and data can be seen at https://github.com/IDEA-XL/RAPM.
Learning and Current Prediction of PMSM Drive via Differential Neural Networks
Dec 12, 2024Learning models for dynamical systems in continuous time is significant for understanding complex phenomena and making accurate predictions. This study presents a novel approach utilizing differential neural networks (DNNs) to model nonlinear systems, specifically permanent magnet synchronous motors (PMSMs), and to predict their current trajectories. The efficacy of our approach is validated through experiments conducted under various load disturbances and no-load conditions. The results demonstrate that our method effectively and accurately reconstructs the original systems, showcasing strong short-term and long-term prediction capabilities and robustness. This study provides valuable insights into learning the inherent dynamics of complex dynamical data and holds potential for further applications in fields such as weather forecasting, robotics, and collective behavior analysis.
ICODE: Modeling Dynamical Systems with Extrinsic Input Information
Nov 21, 2024



Learning models of dynamical systems with external inputs, that may be, for example, nonsmooth or piecewise, is crucial for studying complex phenomena and predicting future state evolution, which is essential for applications such as safety guarantees and decision-making. In this work, we introduce \emph{Input Concomitant Neural ODEs (ICODEs)}, which incorporate precise real-time input information into the learning process of the models, rather than treating the inputs as hidden parameters to be learned. The sufficient conditions to ensure the model's contraction property are provided to guarantee that system trajectories of the trained model converge to a fixed point, regardless of initial conditions across different training processes. We validate our method through experiments on several representative real dynamics: Single-link robot, DC-to-DC converter, motion dynamics of a rigid body, Rabinovich-Fabrikant equation, Glycolytic-glycogenolytic pathway model, and heat conduction equation. The experimental results demonstrate that our proposed ICODEs efficiently learn the ground truth systems, achieving superior prediction performance under both typical and atypical inputs. This work offers a valuable class of neural ODE models for understanding physical systems with explicit external input information, with potential promising applications in fields such as physics and robotics.
NODE-Adapter: Neural Ordinary Differential Equations for Better Vision-Language Reasoning
Jul 11, 2024



In this paper, we consider the problem of prototype-based vision-language reasoning problem. We observe that existing methods encounter three major challenges: 1) escalating resource demands and prolonging training times, 2) contending with excessive learnable parameters, and 3) fine-tuning based only on a single modality. These challenges will hinder their capability to adapt Vision-Language Models (VLMs) to downstream tasks. Motivated by this critical observation, we propose a novel method called NODE-Adapter, which utilizes Neural Ordinary Differential Equations for better vision-language reasoning. To fully leverage both visual and textual modalities and estimate class prototypes more effectively and accurately, we divide our method into two stages: cross-modal prototype construction and cross-modal prototype optimization using neural ordinary differential equations. Specifically, we exploit VLM to encode hand-crafted prompts into textual features and few-shot support images into visual features. Then, we estimate the textual prototype and visual prototype by averaging the textual features and visual features, respectively, and adaptively combine the textual prototype and visual prototype to construct the cross-modal prototype. To alleviate the prototype bias, we then model the prototype optimization process as an initial value problem with Neural ODEs to estimate the continuous gradient flow. Our extensive experimental results, which cover few-shot classification, domain generalization, and visual reasoning on human-object interaction, demonstrate that the proposed method significantly outperforms existing state-of-the-art approaches.
Conceptual Codebook Learning for Vision-Language Models
Jul 02, 2024



In this paper, we propose Conceptual Codebook Learning (CoCoLe), a novel fine-tuning method for vision-language models (VLMs) to address the challenge of improving the generalization capability of VLMs while fine-tuning them on downstream tasks in a few-shot setting. We recognize that visual concepts, such as textures, shapes, and colors are naturally transferable across domains and play a crucial role in generalization tasks. Motivated by this interesting finding, we learn a conceptual codebook consisting of visual concepts as keys and conceptual prompts as values, which serves as a link between the image encoder's outputs and the text encoder's inputs. Specifically, for a given image, we leverage the codebook to identify the most relevant conceptual prompts associated with the class embeddings to perform the classification. Additionally, we incorporate a handcrafted concept cache as a regularization to alleviate the overfitting issues in low-shot scenarios. We observe that this conceptual codebook learning method is able to achieve enhanced alignment between visual and linguistic modalities. Extensive experimental results demonstrate that our CoCoLe method remarkably outperforms the existing state-of-the-art methods across various evaluation settings, including base-to-new generalization, cross-dataset evaluation, and domain generalization tasks. Detailed ablation studies further confirm the efficacy of each component in CoCoLe.